2026
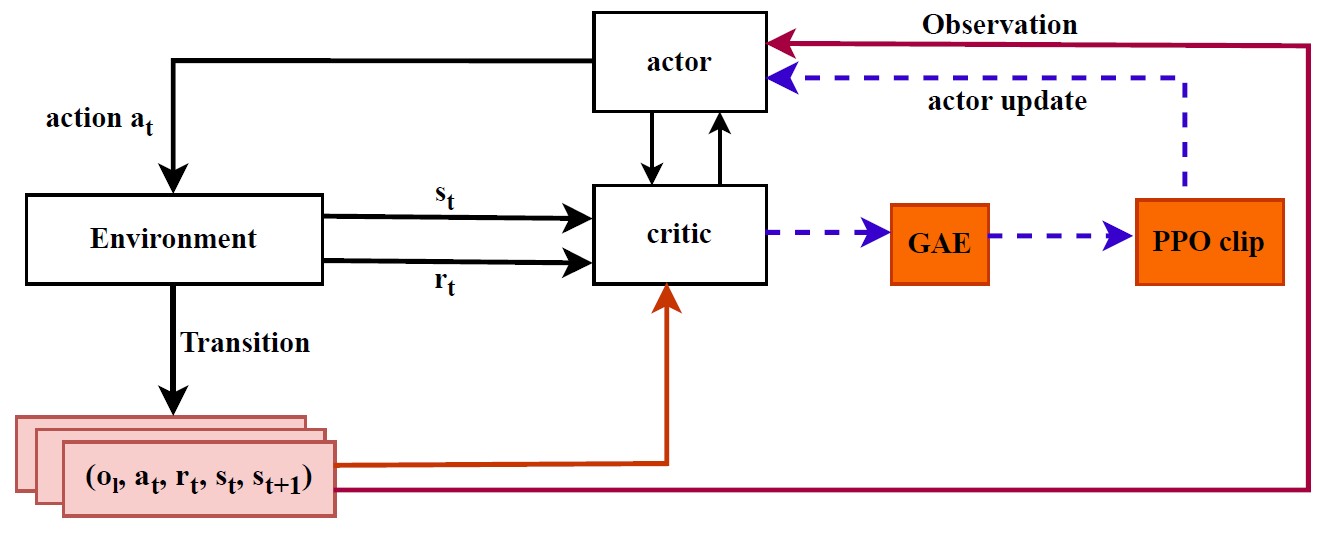
Energy-Efficient Downlink Power Allocation in User-Centric Cell-Free Massive MIMO Networks Using Hybrid Deep Reinforcement Learning Algorithm.
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
IEEE Transactions on Communications Under review. 2026
Cell-free massive multiple-input multiple-output (CF-mMIMO) systems constitute a promising architecture for next-generation wireless communications due to their ability to provide uniform coverage, enhanced spectral efficiency (SE), and advanced interference management. However, downlink power allocation in such systems remains a critical challenge owing to the coordination of distributed access points (APs), strict per- AP power constraints, and dynamic channel conditions. In this paper, we propose a hybrid deep reinforcement learning–based power allocation scheme that combines Multi-Agent Deep Deterministic Policy Gradient (MADDPG) and Proximal Policy Optimization (PPO) to maximize energy efficiency (EE) in usercentric (UC) CF-mMIMO networks. the proposed Multi-agent DRL follows centralized training and decentralized execution (CTDE) paradigm to address the non-stationarity inherent in multi-agent environments. The integration of PPO enables to stabilize policy updates and address the fluctuations induced by interference dynamics, while the centralized critic captures global network state. Simulation results demonstrate significant improvements in EE, SE, and stability after convergence compared to benchmarks DRL and classical methods. Notably, the proposed method achieves an EE of up to 580 Mbit/joule, while the average SE exceeds 17 bps/Hz. Moreover, the algorithm also maintains user-level reliability measure by minimum per-UE SE which median exceed 9 bps/Hz, thereby preventing resource starvation while preserving strict QoS guarantees. These finding confirm the effectiveness and robust of the proposed approach for large-scale UC CF-mMIMO systems, paving the way for costeffective and scalable deployments.
Energy-Efficient Downlink Power Allocation in User-Centric Cell-Free Massive MIMO Networks Using Hybrid Deep Reinforcement Learning Algorithm.
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
IEEE Transactions on Communications Under review. 2026
Cell-free massive multiple-input multiple-output (CF-mMIMO) systems constitute a promising architecture for next-generation wireless communications due to their ability to provide uniform coverage, enhanced spectral efficiency (SE), and advanced interference management. However, downlink power allocation in such systems remains a critical challenge owing to the coordination of distributed access points (APs), strict per- AP power constraints, and dynamic channel conditions. In this paper, we propose a hybrid deep reinforcement learning–based power allocation scheme that combines Multi-Agent Deep Deterministic Policy Gradient (MADDPG) and Proximal Policy Optimization (PPO) to maximize energy efficiency (EE) in usercentric (UC) CF-mMIMO networks. the proposed Multi-agent DRL follows centralized training and decentralized execution (CTDE) paradigm to address the non-stationarity inherent in multi-agent environments. The integration of PPO enables to stabilize policy updates and address the fluctuations induced by interference dynamics, while the centralized critic captures global network state. Simulation results demonstrate significant improvements in EE, SE, and stability after convergence compared to benchmarks DRL and classical methods. Notably, the proposed method achieves an EE of up to 580 Mbit/joule, while the average SE exceeds 17 bps/Hz. Moreover, the algorithm also maintains user-level reliability measure by minimum per-UE SE which median exceed 9 bps/Hz, thereby preventing resource starvation while preserving strict QoS guarantees. These finding confirm the effectiveness and robust of the proposed approach for large-scale UC CF-mMIMO systems, paving the way for costeffective and scalable deployments.
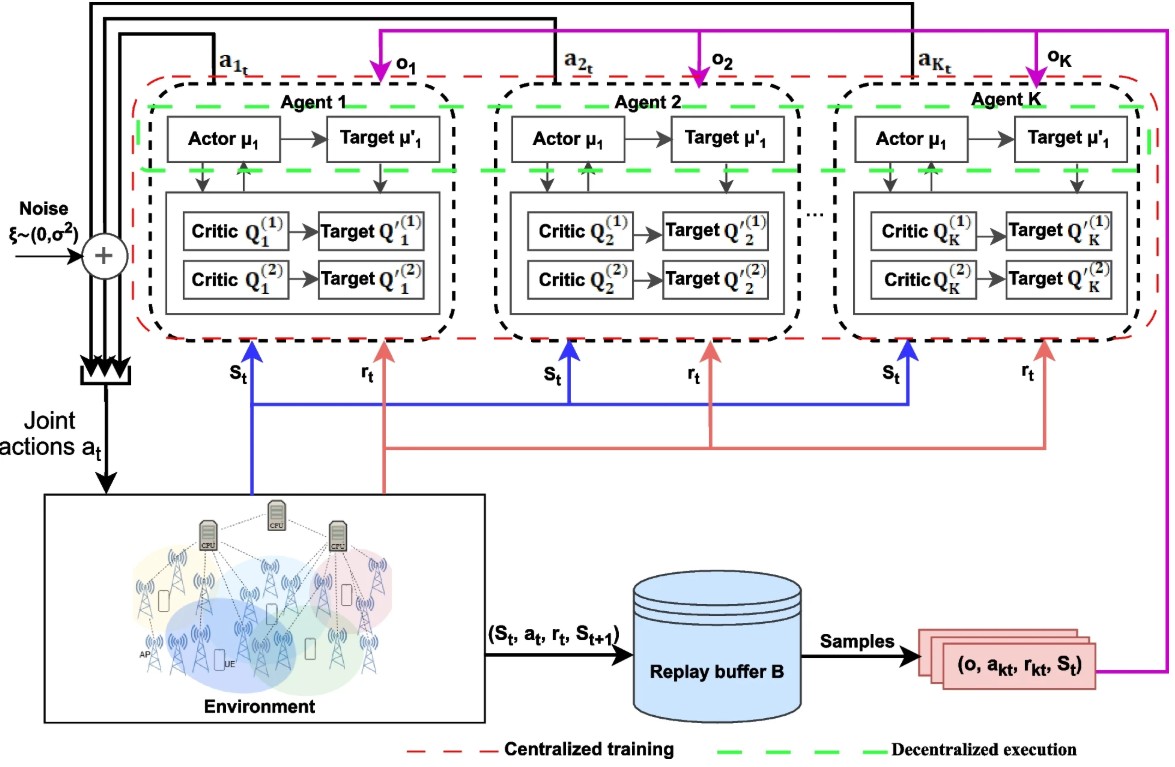
Optimizing uplink power control for energy efficiency in mmWave user-centric cell-free massive MIMO with deep reinforcement learning
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
Journal of Engineering and Applied Science 2026
User-centric (UC) Cell-Free massive Multiple-Input Multiple-Output (CF-mMIMO) millimeter-wave (mmWave) networks are a promising solution to meet the performance requirements of next-generation wireless systems. However, maximizing energy efficiency in dense deployments remains challenging due to coordination overhead and highly dynamic propagation conditions. This work addresses uplink power control in UC CF-mMIMO networks and proposes a Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (MATD3) approach trained under a centralized training and decentralized execution (CTDE) paradigm. The simulations are performed in a PyTorch library and rely on 3GPP TR 38.901 specification for the mmWave channel model over a UC architecture with 35 user equipments (UEs) and 100 distributed access points (APs). Simulation results indicate clear gains over both DRL baselines and conventional optimization methods. In particular, the proposed scheme reaches an energy efficiency of up to 380 Mbit/joule and maintains spectral efficiencies above 18 bps/Hz. Moreover, the method also preserves user-level reliability with a median minimum per-user spectral efficiency remains above 9 bps/Hz, and the Jain fairness index reaches 0.96, preventing resource starvation while maintaining strict QoS guarantees. These findings demonstrate that multi-agent cooperation enables robust and energy-efficient power control policies, paving the way for cost-effective and scalable UC CF-mMIMO deployments.
Optimizing uplink power control for energy efficiency in mmWave user-centric cell-free massive MIMO with deep reinforcement learning
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
Journal of Engineering and Applied Science 2026
User-centric (UC) Cell-Free massive Multiple-Input Multiple-Output (CF-mMIMO) millimeter-wave (mmWave) networks are a promising solution to meet the performance requirements of next-generation wireless systems. However, maximizing energy efficiency in dense deployments remains challenging due to coordination overhead and highly dynamic propagation conditions. This work addresses uplink power control in UC CF-mMIMO networks and proposes a Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (MATD3) approach trained under a centralized training and decentralized execution (CTDE) paradigm. The simulations are performed in a PyTorch library and rely on 3GPP TR 38.901 specification for the mmWave channel model over a UC architecture with 35 user equipments (UEs) and 100 distributed access points (APs). Simulation results indicate clear gains over both DRL baselines and conventional optimization methods. In particular, the proposed scheme reaches an energy efficiency of up to 380 Mbit/joule and maintains spectral efficiencies above 18 bps/Hz. Moreover, the method also preserves user-level reliability with a median minimum per-user spectral efficiency remains above 9 bps/Hz, and the Jain fairness index reaches 0.96, preventing resource starvation while maintaining strict QoS guarantees. These findings demonstrate that multi-agent cooperation enables robust and energy-efficient power control policies, paving the way for cost-effective and scalable UC CF-mMIMO deployments.
2025
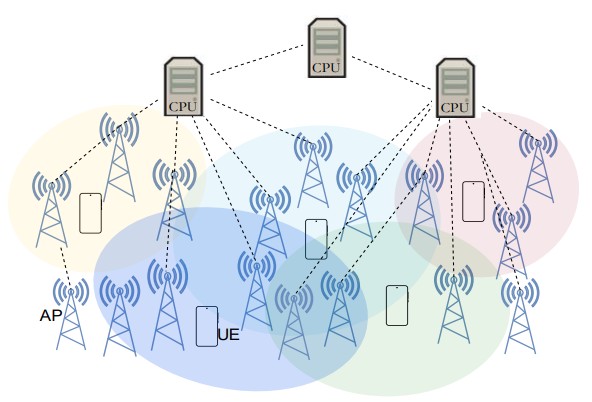
Deep Reinforcement Learning-based Power Allocation for Maximizing Energy Efficiency in mmWave Cell-free Massive MIMO
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
International Journal of Intelligent Engineering and Systems 2025
With the rapid increase in mobile data traffic and connected devices, energy-efficient resource allocation in cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) systems has emerged as a key challenge for beyond5G networks. Existing optimization techniques often struggle scaling large user-centric (UC) architectures, particularly under millimeter wave (mmWave) frequencies, and frequently overlook fairness across users, which is essential for robust and practical deployment. In this paper, we propose a hybrid Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (MATD3) with Proximal Policy Optimization (PPO), that jointly optimizes downlink power allocation and fairness in UC CF-mMIMO systems. This approach leverages the sample exploration of MATD3 and the stability update of PPO, enabling robust learning in dynamic multi-agent environments. Furthermore, we incorporate the minimum per-user spectral efficiency to address fairness. The proposed simulation results demonstrate 430 Mbit/joule energy efficiency and 17.6 bps/Hz spectral efficiency compared to traditional optimization techniques. These findings validate the superior capability of proposed algorithm providing a promising solution for energy-efficient and fairness in large-scale UC CF-mMIMO deployments.
Deep Reinforcement Learning-based Power Allocation for Maximizing Energy Efficiency in mmWave Cell-free Massive MIMO
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
International Journal of Intelligent Engineering and Systems 2025
With the rapid increase in mobile data traffic and connected devices, energy-efficient resource allocation in cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) systems has emerged as a key challenge for beyond5G networks. Existing optimization techniques often struggle scaling large user-centric (UC) architectures, particularly under millimeter wave (mmWave) frequencies, and frequently overlook fairness across users, which is essential for robust and practical deployment. In this paper, we propose a hybrid Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (MATD3) with Proximal Policy Optimization (PPO), that jointly optimizes downlink power allocation and fairness in UC CF-mMIMO systems. This approach leverages the sample exploration of MATD3 and the stability update of PPO, enabling robust learning in dynamic multi-agent environments. Furthermore, we incorporate the minimum per-user spectral efficiency to address fairness. The proposed simulation results demonstrate 430 Mbit/joule energy efficiency and 17.6 bps/Hz spectral efficiency compared to traditional optimization techniques. These findings validate the superior capability of proposed algorithm providing a promising solution for energy-efficient and fairness in large-scale UC CF-mMIMO deployments.
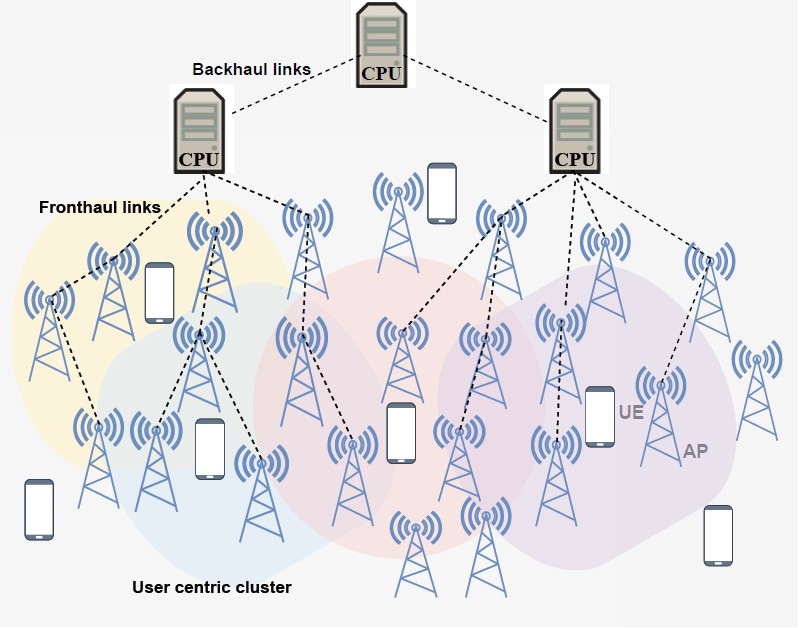
Multi-Agent Deep Reinforcement Learning-Based Power Control for Energy-Efficient User-Centric Cell-Free Massive MIMO
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
Physical CommunicationsUnder review. 2025
Cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) networks are positioned as a major pillar of beyond-5G wireless systems, offering better coverage and increased spectral efficiency due to the distributed deployment of multiple access points (APs) to serve multiple users in a wide coverage area. This promises effective interference mitigation and significant enhancement in system capacity. Nevertheless, optimizing energy efficiency under practical constraints remains a crucial challenge. Conventional optimization-based techniques often struggle scaling large user-centric (UC) CF-mMIMO architectures and frequently overlook fairness among users, which is essential for robust and practical deployment. To address this gap, this paper proposes a Multi-Agent Deep Deterministic Policy Gradient (MADDPG)-based scheme for joint uplink power control and fairness optimization in UC CF-mMIMO networks. The problem is formulated as a Markov game, where users equipments are considered as agents and optimize their transmit power under minimum per-user spectral efficiency and maximum power constraints. Simulation results under both perfect and imperfect CSI, varying transmit power and network density, demonstrate that the proposed algorithm consistently outperforms benchmark methods. In particular, it achieves a median energy efficiency of approximately 430 Mbit/joule, corresponding to improvements of about 19%, 23%, and 71% compared to multi-agent proximal policy optimization (MAPPO), Twin Delayed Deep Deterministic Policy Gradient (TD3), and DDPG, respectively. In terms of spectral efficiency, the proposed method reaches a median value of about 15 bps/Hz, while the minimum spectral efficiency per-UE exceeds 6.5 bps/Hz, indicating improved fairness. The proposed scheme remains robust across network densities, and under transmit power levels. These findings highlight the scalability and practicality of the MDDPG-based power control for next-generation self-optimizing wireless networks.
Multi-Agent Deep Reinforcement Learning-Based Power Control for Energy-Efficient User-Centric Cell-Free Massive MIMO
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
Physical CommunicationsUnder review. 2025
Cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) networks are positioned as a major pillar of beyond-5G wireless systems, offering better coverage and increased spectral efficiency due to the distributed deployment of multiple access points (APs) to serve multiple users in a wide coverage area. This promises effective interference mitigation and significant enhancement in system capacity. Nevertheless, optimizing energy efficiency under practical constraints remains a crucial challenge. Conventional optimization-based techniques often struggle scaling large user-centric (UC) CF-mMIMO architectures and frequently overlook fairness among users, which is essential for robust and practical deployment. To address this gap, this paper proposes a Multi-Agent Deep Deterministic Policy Gradient (MADDPG)-based scheme for joint uplink power control and fairness optimization in UC CF-mMIMO networks. The problem is formulated as a Markov game, where users equipments are considered as agents and optimize their transmit power under minimum per-user spectral efficiency and maximum power constraints. Simulation results under both perfect and imperfect CSI, varying transmit power and network density, demonstrate that the proposed algorithm consistently outperforms benchmark methods. In particular, it achieves a median energy efficiency of approximately 430 Mbit/joule, corresponding to improvements of about 19%, 23%, and 71% compared to multi-agent proximal policy optimization (MAPPO), Twin Delayed Deep Deterministic Policy Gradient (TD3), and DDPG, respectively. In terms of spectral efficiency, the proposed method reaches a median value of about 15 bps/Hz, while the minimum spectral efficiency per-UE exceeds 6.5 bps/Hz, indicating improved fairness. The proposed scheme remains robust across network densities, and under transmit power levels. These findings highlight the scalability and practicality of the MDDPG-based power control for next-generation self-optimizing wireless networks.
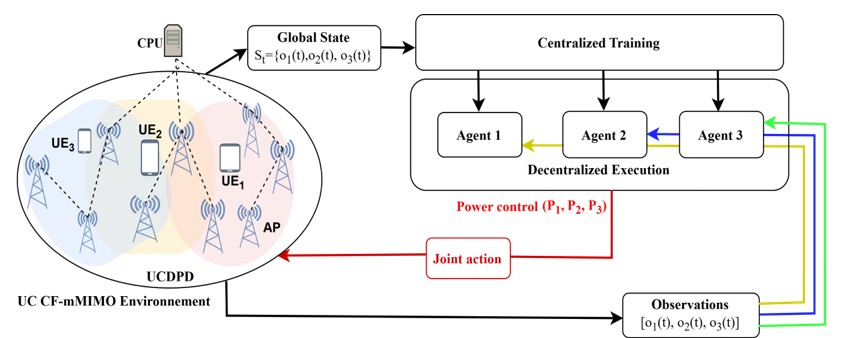
Deep Reinforcement Learning-based Power Control Optimization for Maximizing Energy Efficiency in mmWave User-Centric Cell-Free Massive
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
IET CommunicationsUnder review. 2025
Millimeter Wave (mmWave) Cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) is a key architecture for beyond 5G (B5G) networks, nevertheless its energy efficiency (EE) remains constrained by dense access points (APs) deployments, rapidly varying channels, and the strict low-latency requirements for real-time decisions. Classical optimization techniques and Machine Learning (ML) or existing Deep Reinforcement Learning-based (DRL) solutions exhibit limited scalability, rely on centralized global CSI, and insufficiently capture dynamic User-Centric (UC) topology and mmWave channel variations. To address these limitations, we propose a joint uplink power control and topology optimization framework. It leverages a multi-agent Deep Deterministic Twin Policy Gradient (MATD3) algorithm combined with an adaptive AP-User Equipment (UE) association mechanism termed UC Dynamic Proximity, and demand (UCDPD). Within a centralized training with decentralized execution (CTDE) paradigm to ensure fast convergence and stability, while UCDPD dynamically forms adaptative UC clusters to reduce state dimensionality. Simulation results demonstrate that the proposed method outperforms standalone MATD3, baselines single and multi-agent DRL and traditional techniques. It achieves up to 495 Mbit/joule in EE and average spectral efficiency (SE) above 17 bps/Hz. This represents significant improvement about 10-20 %, and 32-60% compared to reference multi-agent and single-agent schemes respectively. The proposed framework remains robust across network densities, under transmit power levels (15-100 mW) and different learning rates. These findings underscore the scalability and practicality of the proposed algorithm for next-generation self-optimizing wireless communications.
Deep Reinforcement Learning-based Power Control Optimization for Maximizing Energy Efficiency in mmWave User-Centric Cell-Free Massive
Dramane Diarra, Heywood Ouma Absaloms, Philip Kibet Langat
IET CommunicationsUnder review. 2025
Millimeter Wave (mmWave) Cell-free massive Multiple-Input Multiple-Output (CF-mMIMO) is a key architecture for beyond 5G (B5G) networks, nevertheless its energy efficiency (EE) remains constrained by dense access points (APs) deployments, rapidly varying channels, and the strict low-latency requirements for real-time decisions. Classical optimization techniques and Machine Learning (ML) or existing Deep Reinforcement Learning-based (DRL) solutions exhibit limited scalability, rely on centralized global CSI, and insufficiently capture dynamic User-Centric (UC) topology and mmWave channel variations. To address these limitations, we propose a joint uplink power control and topology optimization framework. It leverages a multi-agent Deep Deterministic Twin Policy Gradient (MATD3) algorithm combined with an adaptive AP-User Equipment (UE) association mechanism termed UC Dynamic Proximity, and demand (UCDPD). Within a centralized training with decentralized execution (CTDE) paradigm to ensure fast convergence and stability, while UCDPD dynamically forms adaptative UC clusters to reduce state dimensionality. Simulation results demonstrate that the proposed method outperforms standalone MATD3, baselines single and multi-agent DRL and traditional techniques. It achieves up to 495 Mbit/joule in EE and average spectral efficiency (SE) above 17 bps/Hz. This represents significant improvement about 10-20 %, and 32-60% compared to reference multi-agent and single-agent schemes respectively. The proposed framework remains robust across network densities, under transmit power levels (15-100 mW) and different learning rates. These findings underscore the scalability and practicality of the proposed algorithm for next-generation self-optimizing wireless communications.